
Hello!
I’m Yuanjun Lin
My world revolves around transforming complex data into actionable insights and meaningful impact. With a solid data science foundation from Duke Kunshan University and currently enhancing my analytics skills at UC Berkeley, I specialize in data science applications that solve real problems. From creating smart algorithms to tackling social issues through technology, I’m driven by the power of data to make a difference. Explore my projects and join me on a journey where data meets purpose.
Featured Works
Neural Network-Based Heuristic Selection for Optimization Challenge
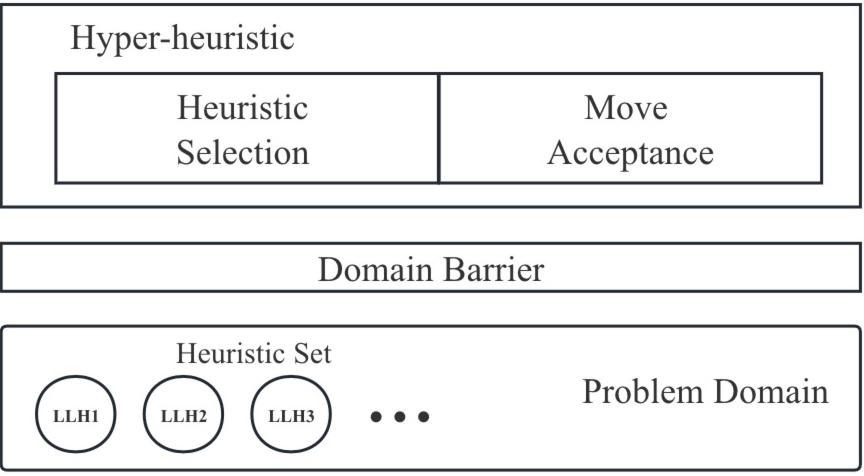
An Illustration of Selection Hyper-Heuristic Framework
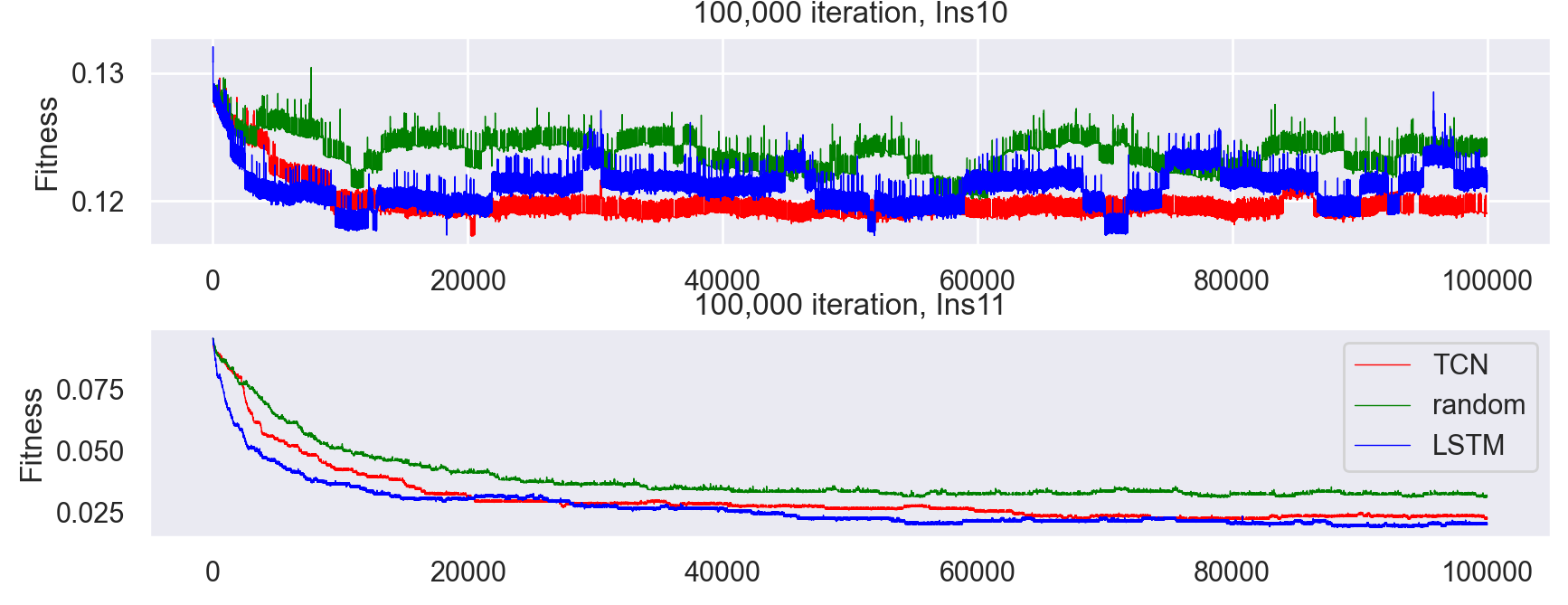
Fitness of Model Solutions on Bin Packing Instances
This is a two-person project published in 2023 IEEE CEC, where I was in charge of generating learnable data from a previous Java hyperheuristic framework, developing the LSTM-based selection hyperheuristic (SHH), and finally performance evaluation.
In combinatorial optimization, the quest for efficiency often leads to the exploration of NP-hard problems as a testing field. Our project pioneers the use of neural networks, specifically LSTM and TCN architectures, to establish an SHH that is able to learn from previous HHs and utilize the advantage they have under different circumstances such as the nature of the instance and problem domain. This approach not only elevates the adaptability of heuristic selection across varied problem instances but also encapsulates the collective intelligence of multiple selection hyper-heuristics into a unified, efficient system
Genetic Algorithm-based Diversified Article Recommendation System
This is an ongoing independent study on a genetic algorithm (GA) optimized article recommendation system.
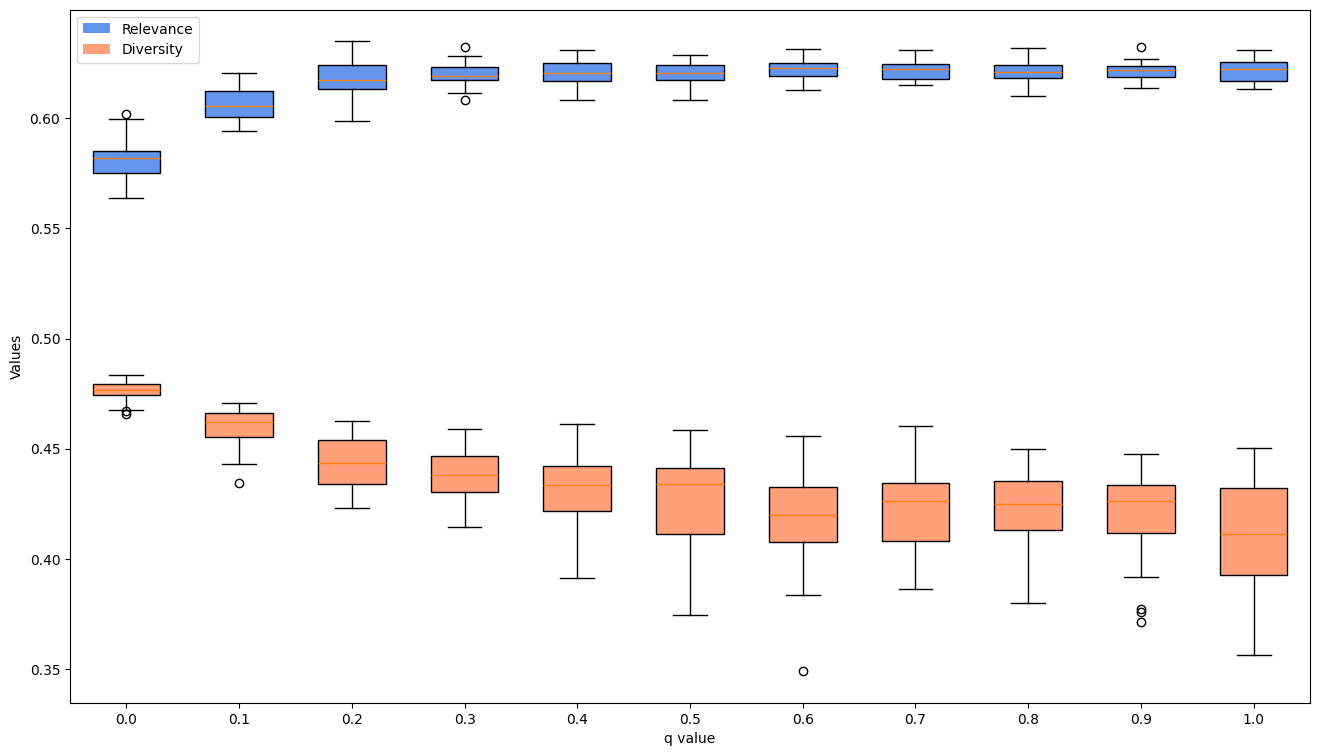
The aim is to finetune the balance between relevance and diversity. Altering conventional similarity assessment methods and incorporating a diversity coefficient, the research tackles the prevalent issue of narrow content scope in content‐based systems. The approach entails detailed data processing and feature extraction to refine recommendation quality and efficiency. Empirical results, evidenced by significant ANOVA outcomes for both relevance and diversity (P < .01), affirm the model’s efficacy in delivering a more engaging and varied content selection to users.
The structure is complete with results, yet some improvements such as more efficient Doc2Vec preprocessing and an improved structure with multi-fold weight that is partially inspired by maximal marginal relevance algorithm are being implemented.

An Illustration of Selection Hyper-Heuristic Framework
Fitness of Model Solutions on Bin Packing Instances